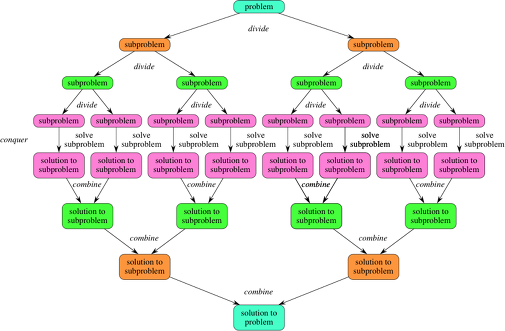
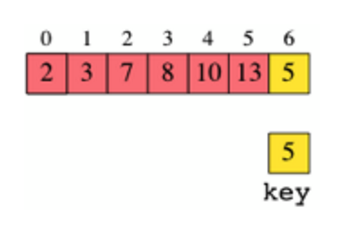
Sweep은 “쓸다”라는 의미를 가지고있는데, 스윕 라인 알고리즘은 빗자루로 먼지를 쓸어내듯이 특정 방향을 따라 스위핑하면서 점 또는 선을 확인하며 답을 찾아가는 알고리즘이다. 선분의 교차 여부, 구간 겹, 점의 분포등을 계산할 수 있기때문에 주로 시/공간의 겹침, 자원할당, 스케쥴링 문제를 다룰때 해결할 수 있는다. 나도 마찬가지로 회의실 예약 관련 Tool을 만들다 접하게되었다. 스윕 라인 알고리즘의 문제 해결과정은 대부분 이렇다:모든 데이터를 특정 기준에따라 정렬한다.스위핑 라인을 이동시키며 데이터를 하나씩 처리한다. 내 경우 회의실이 비는 시간을 파악하기 위해서 사용했는데, 이를 단순화한 예시로 스윕 라인 알고리즘을 알아보자. 3개의 회의실이 있고, 이미 예약된 회의가 있다.이미 예약된 회의가 ..