파일 시스템(Filesystem)은 파일들이 저장공간에 어떻게 이름 지어지고, 저장되고 가져와지는지에 대한 규약이다. 물리적인 공간에 저장된 데이터를 논리적으로 매핑하여 읽고, 데이터를 검색하고 저장하는 등 관리할 수 있게 한다. 대표적인 운영체제에서 사용하고 있는 파일 시스템의 종류는 다음과 같다.
| Windows | FAT*, NTFS |
| Linux | Ext* |
| Mac OS | HFS, APFS |
| Solaris | ZFS |
맥에서 diskutil info / 를 치면 현재 볼륨에 대한 파일 시스템 정보를 볼 수 있는데, APFS를 사용중임을 알 수 있다.

파일 메타데이터
파일 시스템을 추상화해보면 메타 영역과 데이터 영역으로 나누어 볼 수 있다. 메타 영역은 파일 관리를 위한 파일의 이름, 크기, 생성일, 위치 등의 정보가 기록되어있는데, 이를 메타 데이터(meta-data)라고 한다. 파일 시스템은 이러한 메타 데이터를 바탕으로 파일을 관리하고 있다. 맥에서 mdls <파일명>을 치면 다음과 같이 파일의 메타 데이터를 볼 수 있다. (간략하게는 ls -l로 볼 수 있다.)

클러스터
클러스터는 파일 시스템에서 파일에 대한 디스크 공간을 할당하는 단위이다. 아래 사진은 내 맥의 파일 시스템 정보인데, 보면 Allocation Block Size: 4096 Bytes라고 된 부분이 있을 것이다. 이것이 바로 클러스터의 크기다.

클러스터는 디스크의 물리적 최소단위인 섹터(sector - 512 Byte)를 묶은 단위로 만들어지는데, 섹터 단위로 입출력을 처리하면 시간이 오래 걸리므로 여러 섹터를 묶어 한번에 처리한다. 예로, 1MB의 파일을 기록하려고한다면 1024KB / 4KB = 256번의 처리가 필요하지만, 섹터단위로 간다면 2,048번의 처리가 필요하다. 이렇게 I/O를 줄이기 위해서 디스크 용량에 따라 적절한 사이즈의 클러스터 크기가 지정된다. (물론 원하면 바꿀수 있다.)

"TB시대에 겨우 4KB...?! 조금 크면 좋을 것같은데?" 라는 생각이 들 수 있다. 그전에 클러스터 사이즈에 따른 단편화(fragmentation)현상을 먼저 살펴보자. 4KB 클러스터에 100B 짜리 파일을 저장할 경우, 실제 물리적 공간은 100B 밖에 차지하지 않지만 논리적으로는 3996Byte가 낭비된다.

딱 한글자만 적어서 실제로 2B를 차지하는 텍스트 파일 4개를 만들어보았다. 이 4개의 파일은 cluster_sample이라는 디렉토리에 들어있는데, 외부에서 확인했을때 디렉토리의 크기는 8B가되어야 할 것이다. 하지만 실제로 확인해보면 크기는 8바이트이지만 디스크에서는 16KB를 차지하고 있다고 뜬다. 클러스터 크기에의해 단편화가 발생한 것이다.
코로나가 한창일때 저녁 6시 이후로는 최대 2인 밖에 저녁을 먹지 못했었는데, 보통 테이블이 4인석이니 2인만큼의 공간이 낭비될 수 밖에없었다. 완전히 모르는 사람인데 합석도 할 수없고...그 자리는 못쓰는 공간이 된다. 이야기가 좀 샜는데, 이러한 논리 데이터와 물리적 저장공간의 간극으로 인해 발생하는 못 쓴느 공간을 슬랙 공간(Slack space)이라고 한다.

그래서 클러스터가 크면 I/O는 빨라질 수 있지만, 단편화 문제로인해 디스크 공간활용을 제대로 못할 수 있다는 장단점이 있다.
운영체제별 파일 시스템
옛날에 다들 자료 저장할때 USB를 들고다니던 시절, 파일 시스템과 마주할일이 많았다. USB를 FAT32로 포맷하고 (뭐가 다른지, 좋은지도 몰랐음) 6GB짜리 영화를 넣으려는데 도대체 넣을 수 가 없는것이다. 찾아보니 FAT32 파일 시스템은 4GB이상의 파일을 R/W할 수 없었다. 그래서 NTFS로 기껏 변경했지만 또 맥에서 사용하려고 보니 NTFS로 포맷된 USB 속 파일들을 맥에서 R/W 할 수 없었다.
Windows 파일 시스템 - FAT
FAT 12, FAT 16은 너무 오래된 시스템이니 넘어가고, FAT32부터 보자. FAT32는 "File Allocation Table 32"의 약자다. 이름부터 본인은 32GB밖에 안된다고 적어두었다. FAT32는 32bit 파일 시스템이기 때문에 파일 하나가 2의 32승인 4GB를 넘어가면 안된다는 크리티컬한 제약조건이 있지만 FAT32는 NTFS보다 단순한 구조로 윈도우외에도 Linux, 맥등에서도 사용가능하다는 이점이있다.

FAT는 파일을 연결할당(Linked allocation)하는데, 파일을 연결 리스트(Linked list)로 관리하는 것을 말한다. 연결 리스트는 직접 액세스가 불가능하고 헤드부터 순차적으로 따라가야하기 때문에 검색 성능이 좋지 않다. 또한 뒤에 링크된 리스트에 대한 포인터를 저장하는 공간이 추가로 필요하다. 중간에 링크가 끊어지는 경우 파일이 심각하게 손상되어버리기때문에 안정성도 다소 낮은편이다.
또 하나의 특징이라고하면, FAT32는 클러스터의 크기를 4KB~32KB까지 설정할 수 있다. (큰 편이다.) 그리고 이름에 공백을 포함할 수 없고 . " / \ [ ] : ; | = , 같은 문자열들이 포함될경우 제대로 작동하지 않을 수 있다. (Microsoft왈: 예기치 않은 문제)
- 장점: 범용성
- 단점: 안정성, 속도
Windows - NTFS
NTFS는 FAT의 안정성과 속도 문제를 해결하기 위해 등장했다. VBR / MFT / DATA 영역으로 나누어지며, NTFS는 파일 암호화, 압축, 숨김, 읽기 전용등 다양한 기능을 지원하기때문에 FAT보다 복잡한 구조를 가지고 있다. 또한 제작사인 Microsoft에서 세부 스펙을 공개하지않아 다른 운영체제에서 호환이 잘 되지않는다. (지원은 하지만, 미흡)
- VBR(Volume Boot Record): 볼륨, 클러스터 크기, 부트코드 부트 섹터 정보
- MFT(Master File Table): 볼륨에 존재하는 모든 파일, 디렉토리에 대한 메타 데이터

대소문자에 따른 파일 이름 구별이 없어, ReadMe.txt 와 README.txt는 한 디렉토리에 공존할 수 없으며, 파일 이름에는 ? " / \ < > * | : 가 포함될 수 없다. 클러스터 크기는 4KB, 64비트 파일 시스템으로 최대 파일 크기는 16TB다.
Linux - ext
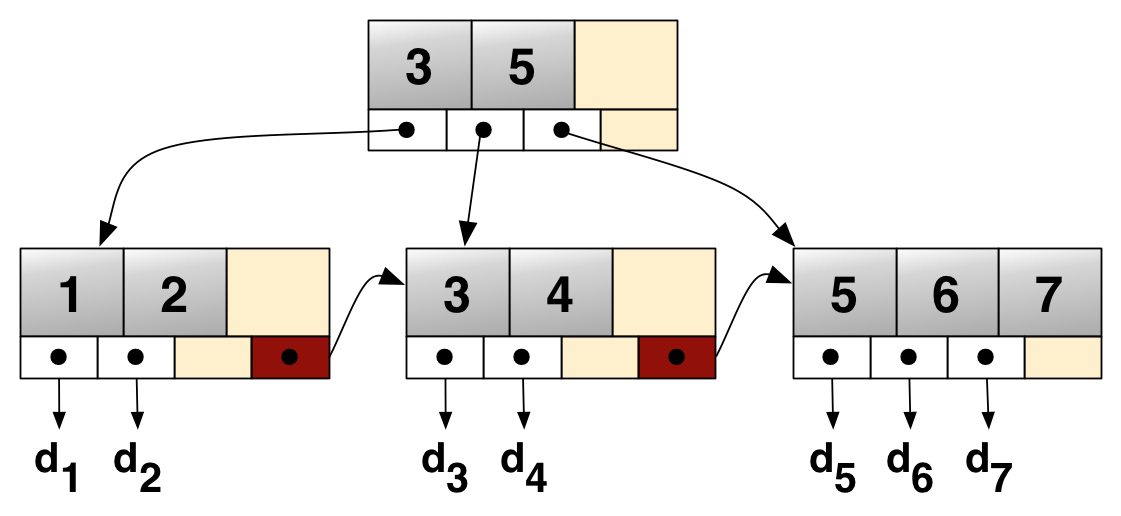
ext는 1부터 4까지 발전해왔다. ext1부터의 발전사는 FAT~NTFS 등과 비슷하기때문에 넘어가도록 하고, ext3에는 Hash Tree 인덱싱이 들어갔다는 점을 노트하고싶다. ext3/ext4 파일 시스템에서는 4KB가 넘는 모든 디렉토리에 인덱스를 부여하여 트리 구조를 만들고, 일정한 검색 속도(O(1))로 파일을 찾을 수 있다. Hash Tree는 데이터베이스에서 주로 쓰이는 B+ Tree의 변형이다.
그 외 파일 시스템
ZFS
ZFS는 Solaris에 탑재된 파일 시스템이었으나 오픈소스로 갈라져나와(OpenZFS) 유닉스 계열 시스템에서 사용할 수 있게 되었다. 최강의 파일 시스템이라는 별명이 여기저기서 보이는데, 내용이 다소 어려워서 ㅠㅡㅠ 간략하게 그 특징만 알아보겠다.
- 최초의 128비트 파일 시스템으로 거의 무한대 용량의 파일 크기를 지원한다.
- 파일 시스템 수준에서의 Raid를 지원하는데, Raid란 여러개의 저장 장치를 묶어 고용량/고성능 저장장치 하나와 같은 효과를 얻을 수 있게 해주는 기법이다.
- 파괴된 데이터를 자동으로 복구할 수 있는 방법을 제공한다(scrup)
- Copy-on-write 트랜잭션을 모델을 사용하여, 파일을 수정하는 도중 문제가 발생하더라도 원본 파일의 손상을 막을 수 있다.
HDFS
하둡은 빅테이터 처리와 분석을위한 플랫폼이다. Hadoop Distributed File System, HDFS가 바로 하둡에서 사용하는 파일 시스템이다. HDFS는 하나의 머신에서 처리하기 힘든 대용량 파일을 분산된 서버에 저장 및 처리할 수 있으며 Namenode, Datanode, Client 모듈로 구성되어있다.
- Namenode: HDFS의 구조와 저장된 블록의 위치, 메타 데이터 관리
- Datanode: 파일 데이터
- Client: 사용자가 작성한 프로그램. HDFS에 파일을 R/W

HDFS에서 대용량 파일을 분산하여 저장하기 위해 메타 데이터와 데이터를 분리하고, 메타 데이터를 Namenode에, 데이터는 블록의 기본 크기인 128MB 단위로 잘라서 최소 3개의 복사본을 생성하여 분산 저장한다. 클라이언트는 Namenode에 접근하여 관련한 블록들의 목록과 주소를 가져와서 가장 가까운 위치에 있는 Datanode에서 블록들을 읽어온다.
참고자료
https://gbworld.tistory.com/1080
http://www.parkjonghyuk.net/lecture/2012-2nd-lecture/computersecurity/chap08.pdf
'프로그래밍 > General' 카테고리의 다른 글
| [SSH] UNPROTECTED PRIVATE KEY FILE 해결방법 (0) | 2022.01.31 |
|---|---|
| 내 소스 코드가 실행되기까지의 과정 (1) | 2022.01.27 |
| [운영체제] 프로그램, 프로세스, 스레드 파헤치기 (0) | 2021.12.17 |
| Redis의 개념과 활용법 (0) | 2021.11.16 |
| 맥에서 ANSI 인코딩 txt 파일 읽는 간단한 해결법 (1) | 2021.10.25 |